
 |
Thomas G. Dietterich- computer scientist
|
|

" I am definitely the kind of person that requires an image or a diagram to understand anything mathematical, because the symbols by themselves don’t help me very much."
(links for Thomas G. Dietterich)
|
|
What kind of role do pictures play in your professional field? |

simple UML diagram that states that Every Student is also Person
|
Well, being at this meeting the first thing that comes to mind is the Bayesian Network. This diagrams with a node or a circle as a random variable tell us by the edges and the arrows which variables have a direct influence on some other variable. I think, we also make a lot of use now of something called unified modelling language UML, which is used for building software and models of software. Over the last decade I taught some classes in software engineering. The current philosophy of building software in this languages is that you first build essentially a graphical model of the components and you gradually elaborate those until they become software. There are even formal tools now, so that you can put these drawings into the computer and then turn them into the software eventually. The software is usually very textual. But there are exceptions, there are some graphical programming languages and specification languages that have a spatial aspect to them too. We use UML class diagrams, where we have a box indicating some sort of the components and objects. So if we were describing for instance the objects in this room, you might have class diagram for tables and a table might have some properties including perhaps its location and orientation. Then we might want to describe a whole list of tables, a line of tables, so it have to have another object that would assess that it would have a one to many relationship between the of tables and each individual table. So you can describe hierarchies of objects. That´s the other diagram. Those will be the two primary ones I use most.
|
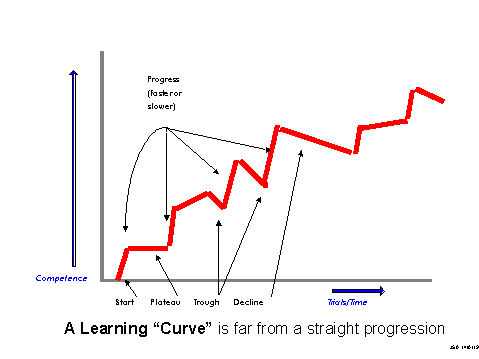
learning curve: a plot of system performance as a function of experience
|
Then of course there are graphs. One of the things we do a lot in learning is that we look at how performance improves as you learn more and more. It typically has some way of measuring performance accuracy or predictive power in some sense or specificity. Then we measure a learning curve. So we might have a plot of system performance as a function of experience. We like our learning curves to rise very quickly which we call steep learning curves. Although in everyday language people say a steep learning curve would be something that is hard to learn. But it´s actually easy to learn, a steep curve goes very quickly up. But the curves you don´t like go up very slowly, so it takes you ten years to become an expert at something. We use those diagrams a lot and we compare and read. Probably in the talks here you´ve seen Bayesian Networks and learning curves mostly.
|
|
So you use images to structure things? |
drawings which try to catch certain topological relationships |
They are all drawings and they´re all abstract in the sense that they´re not depicting anything in the physical world. But they are trying to catch certain topological relationships. If two things are connected in the diagram then there is some relation between them in the world. When they are not connected, the assumption is that there is no direct connection in the world. So you are trying to ofcapture this connectedness.
When we put an arrow between two objects, it´s more an abstract notion that in some way this object influences this other object. It could be any kind of dependency or relationship between two objects.
|
|
Your major medium is the language of mathematics. Do you see mathematics represented in these diagrams you use or is this something different? |
The whole goal is to decompose a complex thing into simple low order relationships between people or objects. |
The Bayesian Network diagram corresponds to a mathematical formula. It´s actually a factorisation of the joint probability distribution into a product of individual smaller distributions. Another way of thinking about what´s happening is that you´re decomposing. One of the examples they are talking about are authors and papers and who cites whom and and citation graphs. You could think of that as ten thousand random variables which have all some very complex relationships. Or you can break it into these smaller relationships that are very simple and then compose out of that this large complex system. The whole goal is to decompose a complex thing into simple low order relationships between people or objects.
|
 |
This afternoon we talked about this granulation. But this is infinite, without boundaries… |
If you had a small amount of data and you had the true model of world and you try to fit to that data, you would get the wrong answer.
|
Yes. We´re always building models which are always incomplete. One of the problems we have is, when you´re learning from data and you have very little data, you can do very little learning.
Depending on how much data is available you want to change the grain size of your model. A lot of the work that´s going into the machine learning has been trying to automatically adapt the complexity of the model to the amount of data that is available, to the complexity of the data. So if you have very simple data then you want only to fit a simple model to it in order to get the best kind of correspondence. Even if the world is very, very complex if you have only small amount of data than you have to adopt an artificially simple hypothesis.
One of the things that I try to teach my students in class is the idea that it would be so extraordinary complicated that, if you had a small amount of data and you had the true model of world and you try to fit to that data, you would get the wrong answer. There you actually get more accurate predictions out of a simplistic model that matches the data. So, we might for example fit a linear model to data even though we know the data corresponds to some non-linear process. Because there is only one set of linear models and there are infinitely more non-linear models so we wouldn´t be able to tell which one was the right one.
|
The most accurate models are actually not correct models. |
But that´s very disturbing. I think that generally of scientifical models. We know their oversimplifications necessarily, that the most accurate models are actually not correct models. Knowing the correct model would not necessarily be useful for making predictions, because we can´t know precisely enough to make those predictions.
My PhD-adviser was an instrumentalist philosopher of science. He felt all scientific theories would only be useful for the predictions they allow us to make and that there is no such thing like reality that could be understood. That is the attitude of an engineer to the world: If it´s useful it is good and if it isn´t useful then it´s unnecessary.
|
|
Maybe that will explain the following question. Because as a non-mathematician I´m wondering always about the use of the factor of infinity in formula. How do you treat this factor? |

They call it asymptopia: The trouble is the behaviour at infinity doesn´t tell you very much of how it would behave in reality.
|
In my field the main time that infinity comes in, is, when we imagine what would our algorithms do, if they were given infinite amounts of sensor data. Would they for instance converge to some correct model or not? Usually it´s mathematically easier to think about those sort of long term asymptotic behaviour than it is to analyse the behaviour when you have a fixed amount of data. Just mathematically you´re able to ignore many things when you go to infinity. The trouble is the behaviour at infinity doesn´t tell you very much of how it would behave in reality. They call it asymptopia, the utopia where you have infinite data and that´s just not a real place. So that theory isn´t actually very useful.
We generally try to avoid these notions of infinity and I suppose there´s another way we´d might think about the infinitely small. If you have data where you´re measuring continous quantities and you might be measuring many significant digits, you have the same problem. Statistically it´s rare that those digits are all really significant. If you don´t have very many datapoints you can´t afford to really look at all those digits. You need to treat that as much more approximated numbers. So it´s the same grain question. You need to use a coarse grainsize when you have very little data. So again, I guess my field is mostly about finite things. Our knowledge of the world is very finite and the data we have for learning about the world ist very finite. So what happens with infinity is really useless to us.
|
|
The panel this week here in Dagstuhl is about probabilistic methods. When I hear probalistic methods I normally think at things like quantum physic, at the spatial probabilities of particles and Heisenberg’s Uncertainty Principle. |
Probability is really a tool for describing incompletely understood things.

Niels Bohr, Werner Heisenberg & Wolfgang Pauli, ca. 1927. © Niels Bohr Archive
|
Right you inhere only an uncertain. The certain things you cannot know.
Probability is really a tool for describing incompletely understood things. So even if true physics were deterministic and Isaac Newton had been correct in some sense and Leibniz before him, we would still find probability useful, because we can use it to capture a situation that we don´t really understand completely. You know, you want to represent your ignorance of the world, so it´s a kind of going beyond what you really know. If you are forced for example to exactly pin down the location of every atom and molecule that makes this table that would be a complicated thing to do. Heisenberg tells you it´s impossible to do it anyway. But you could use probabilities to just say well it´s some distribution and I don´t really care exactly where the things are. Then you can still make useful predictions about things.
|
|
So probality is a tool to keep the world or the models consistent? |
We need some way to represent our uncertainty.

counting ballots: it would be better for us to probablities on it
|
We need some way to represent our uncertainty. If we write everything down in very precise mathematical form it may appear that we know things exactly - that would be untrue. Maybe it is consistency to say something that is as true as we can say we would have to say that we only know with some probability and it´s not exact.
There were some interesting examples in the United States elections recently. We have the illusion that we know exactly know how many vote were cast for each candidate. But we find every time when we count the ballots we get a different number. It´s because we make mistakes, either counting automatically the machines make mistakes or the people counting make mistakes. If you have two hundred million ballots and the difference is one hundred, that means you have to be measuring to some part in a hundred thousand which is very difficult to do. I guess, it´s one on two millions in that case. Our error rate is evidently larger than that, and we can´t actually know who is winning this election. So it would be better for us to put probabilities on it and to make a decision under uncertainty rather than pretending we know the right outcome.
|
|
Which importance does have the web for you?
|
web links as information - a complete sort of mental revolution in computer sciences

It´s a kind of a link structure that we try to reason about.
Now everywhere we look we see networks.
|
I think, that actually the web is the entire reason we´re having this meeting today. Before the web, people working in computers pretty much thought about computers in data as being data points with properties, like a particle in physics has a certain velocity, a certain mass, a charge and maybe some other properties. So we thought of the world as made up of individuals that had properties. Trying to do disease diagnosis or face recognition we would capture a set of properties, represent that as a vector in mathematics. Then we would apply some function to that vector like a neural network or something else to make a decision.
But then the web came along and it turns out that the web has two things: It has the web pages which have content and then it has all the links. People discovered that there is lot of information in the links. Of course now we have Google which is based entirely on the links and ignores the contents of the pages completely. That led to a complete sort of mental revolution in computer sciences and they started thinking about all the linked things there were in the world. As we saw today in the talk about breast cancer the original conception of this was that we have one row in this table for each abnormality in the breast. Then when we go back to that same table but now with that mental change, so we say: Ahh, there´s one visit to the doctor and three abnormalities and then later the same patient visits the doctor another year later and there are two abnormalities. We think of this now as there is one patient, multiple doctor visits and each visit multiple abnormalities - it´s a kind of a link structure that we try to reason about.
I don´t know if you heard about the book from Thomas Kuhn “The Structure of Scientific Revolutions”. The idea is, that the paradigm tells you what to look for and when the paradigm changes you look at the same thing and you see different things. That is what happened exactly in this field. Once we had this mental revolution then we started building computer algorithms that could reason with linked data. Now everywhere we look we see networks. That´s why we have this meeting, because there are two different research communities and we´re both working on a sort of network data. Now they come together to try to compare the two different approaches, trying to understand each others’ worlds and make progress.
|
|
How do you perceive the scientist today under this network conditions ? Is he a node, is he a component in a big composition? |

the scientist is a node, a web-page
|
But the first thing I would think he is a node, like he is a web-page. He has links to his students, to the papers he has read, and there is of course this whole web of ideas where he reads and publishes ideas. I come to Dagstuhl I usually get some new ideas that I hear some people and they influence me and I think about other new ideas. So, there are so many different networks that are operating at the same time. There is the network of some of the people here, who worked with the same adviser I worked with, so we talked about how was our adviser doing. So there is also the kind of academic family. It´s just like a small town, a village, and everyone knows with everyone else.
|
|
I am sorry to make a little rupture. Do you see parallels between abstract images – they do not have to be from the arts but also can be from the sciences – and music? |
When I listen to music, I don´t see images. |
When I listen to music, I don´t see images. I know some people who think of music in image sense.
|
|
What about formal parallels? |
In a computer image the pixel three doesn´t necessarily corresponds to anything.

SN 1997 by Hubble Space Telescope
I think that both images and music as having very rich networks now, because I can only see networks.
|
In an image you have all kinds of a spatial-temporal relationships. I think spatially you have richer relationships than you do in music. In music you can may have many instruments and notes and many chords interacting. It´s made more abstract, it´s not as spatial as images are. Images have such complexly defined relationships and such a variability.
I didn´t mention before that I actually do some image processing research. Most of the work we are talking about on this meeting we might have a variable like height and it always means a personal height. But in a computer image the pixel three doesn´t necessarily corresponds to anything. Sometimes it might be my left eye and sometimes it might be my fingernail. It´s very frustrating, especially when you have a slight change in lighting, a slight change in position. So you have this whole problem that the images in the world have this very complex relationship to each other. Understanding that and inverting that is sort of the goal of computer vision. But it means, that the techniques we have to use are very very different than the ones being used here. I think that both images and music as having very rich networks now, because I can only see networks.
|
|
I see, that we have similar processing structures in certain discipline of science like in astronomy, particle physics or genomics where those large amounts of data are processed. But I see that images more and more scatters into data, especially if I have a look at genomics. How do see this relation between image and data? |
My feeling about molecular biology is that images are now replaced by these networks |
My feeling about molecular biology is that images are now replaced by these networks. Mentally it´s all networks and webs and we have a lot of trouble visualising those. There is a lot of work in tools for trying to visualise these networks, to take advantage of three dimensional human vision to give some way of understanding of interrelations.
|
|
A very personal question to close: What´s your favourite picture at home? |
 |
I think my favourite picture at home is an oil painting. In Oregon the state we have a mountain range and behind that mountain range is high desert - maybe about one thousand to twelve hundred meters above sea level and with a lot of sage brush . So this is a painting looking back at this mountains. But that´s definetly a painting about a place – it is more about the feeling about the place.
|
|
You mean the associations you have with this place, the experiences… |
a dress pattern is also a kind of an image |
Yes. We´re going and visiting there and experiencing that place and the smell.
Now we have another painting that´s probably my wife´s and it is an abstract work in which the base material are patterns for making dresses, that have been folded over many times and then painted in various ways. Vaguely maybe it makes you think of a persons’ face or something. But she likes it. She used to do a lot of sewing when she was younger. She always liked the fact that a dress pattern is also a kind of an image. It´s a bit like a template, because it´s exactly the size of the thing you are trying to make. But now it´s been turned into something abstract, that has lost its property now. I think she likes that idea of the ghost of the metric meaning.
|
I am definitely the kind of person that requires an image or a diagram to understand anything mathematical, because the symbols by themselves don’t help me very much.
|
I wanna tell you one other story. When you try to teach mathematics, it seems that there are different kinds of awareness. Some people really like images and diagrams and other people they just cannot understand them at all. I am definitely the kind of person that requires an image or a diagram to understand anything mathematical, because the symbols by themselves don’t help me very much. But one time I was tutoring students in mathematics, I was trying to explain the cordinate axis. I actually used the corner of a room when I was trying to help the students understand. But one student was completely an algebraic mind and had no physical intuition about space or images at all. Actually the student walked along the cordinate axis as sort of physically feeling to get the concept of a cross. For some people maybe images don´t carry very much in understanding. They can´t exploit the relationships in the image to tell about the world. So that puzzles me, because for me it´s exactly the opposite. Unless I can create an image I can´t understand. It was a very bad mismatch between me and the student. So I keep that in mind when I´m teaching. Maybe the images won´t help, so you need many different media to communicate an idea.
|
|
interview with Tim Otto Roth from 2 February 2005 at Schloß Dagstuhl during the seminar "Probabilistic, Logical and Relational Learning - Towards a Synthesis"
|
|
Links for Thomas G. Dietterich:
Thomas G. Dietterich/Oregon State University
Publications:
 (edited by Thomas G. Dietterich, (edited by Thomas G. Dietterich,
Suzanna Becker & Zoubin Ghahramani)
|






